Нейросети и глубинное обучение (Deep Learning)
Содержание
- Использован материал из сайта machinelearning.ru
Полезные слайды
Введение
Иску́сственные нейро́нная се́ть (artificial neural network, ANN), или просто нейронная сеть — это математическая модель, а также ее программные или аппаратные реализации, построенная в некотором смысле по образу и подобию сетей нервных клеток живого организма.
Нейронные сети — один из наиболее известных и старых методов машинного обучения.
Идея метода сформировалась в процессе изучения работы мозга живых существ. Но нужно помнить, что ИНС гораздо проще своих прототипов, биологических нейронных сетей, до конца не изученных до сих пор.
Основные моменты истории
- В 1958 году Розенблаттом изобретен перцептрон. Перцептрон обретает популярность — его используют для распознавания образов, прогнозирования погоды и т. д. Казалось, что построение полноценного искусственного интеллекта уже не за горами.
- В 1969 году Марвин Минский публикует формальное доказательство ограниченности перцептрона и показывает, что он неспособен решать некоторые задачи, связанные с инвариантностью представлений. Интерес к нейронным сетям резко спадает.
- 1974 год — Пол Дж. Вербос, и А. И. Галушкин одновременно изобретают алгоритм обратного распространения ошибки для обучения многослойных перцептронов. Изобретение не привлекло особого внимания.
- 1982 год — после длительного упадка, интерес к нейросетям вновь возрастает. Хопфилд показал, что нейронная сеть с обратными связями может представлять собой систему, минимизирующую энергию (так называемая сеть Хопфилда). Кохоненом представлены модели сети, обучающейся без учителя (Нейронная сеть Кохонена (Kohonen maps)), решающей задачи кластеризации, визуализации данных (самоорганизующаяся карта Кохонена) и другие задачи предварительного анализа данных.
- 1986 год — Дэвидом И. Румельхартом, Дж. Е. Хинтоном и Рональдом Дж. Вильямсом и независимо и одновременно С. И. Барцевым и В. А. Охониным (Красноярская группа) переоткрыт и существенно развит метод обратного распространения ошибки. Начался взрыв интереса к обучаемым нейронным сетям.
- 2012 - Так называемая deep learning revolution. В 2012 году команда под руководством Джорджа Э. Даля выиграла конкурс «Merck Molecular Activity Challenge», используя многозадачные глубокие нейронные сети для прогнозирования биомолекулярной мишени одного препарата. В 2014 году группа Хохрейтера использовала глубокое обучение для выявления нецелевых и токсических эффектов химических веществ, присутствующих в окружающей среде, в питательных веществах, продуктах домашнего обихода и лекарствах, и выиграла «Tox21 Data Challenge» от Национального института здравоохранения США, Управления по санитарному надзору за качеством пищевых продуктов и медикаментов и NCATS.
- Текущие проблемы: Ничего не известно о границах применимости моделей глубоких нейронных сетей. Не разгадан секрет их суперэффективности в одних задачах и неэффективности в других. Это задачи для грядущих поколений.
Основная сущность
Как и линейные методы классификации и регрессии, по сути нейронные сети выдают ответ вида:
где f — нелинейная функция активации, w — вектор весов, ϕ — нелинейные базисные функции. Обучение нейронных сетей состоит в выборе базисных функций и настройке весов.
Методы обучения
Градиентные методы - это широкий класс оптимизационных алгоритмов, используемых не только в машинном обучении. Здесь градиентный подход будет рассмотрен в качестве способа подбора вектора синаптических весов w в линейном классификаторе. Пусть
- целевая зависимость, известная только на объектах обучающей выборки:
Найдём алгоритм a(x, w), аппроксимирующий зависимость y^*. В случае линейного классификатора искомый алгоритм имеет вид:
где φ(z) играет роль функции активации (в простейшем случае можно положить φ(z) = sign(z)).
Согласно принципу минимизации эмпирического риска для этого достаточно решить оптимизационную задачу: Q(w) = ∑li = 1L(a(xi, w), yi) → minw, где L(a,y) - заданная функция потерь.
Для минимизации применим метод градиентного спуска (gradient descent). Это пошаговый алгоритм, на каждой итерации которого вектор w изменяется в направлении наибольшего убывания функционала Q (то есть в направлении антиградиента):
где η - положительный параметр, называемый темпом обучения (learning rate).
Возможно 2 основных подхода к реализации градиентного спуска:
- Пакетный (batch), когда на каждой итерации обучающая выборка просматривается целиком, и только после этого изменяется w. Это требует больших вычислительных затрат.
- Стохастический (stochastic/online), когда на каждой итерации алгоритма из обучающей выборки каким-то (случайным) образом выбирается только один объект. Таким образом вектор w настраивается на каждый вновь выбираемый объект.
чаще всего используется именно стохастический градиентный спуск с мультистартом (из различных начальных точек), поскольку функционал качества нейросетевых алгоритмов как правило устроен очень сложно и имеет огромное число локальных минимумов разного масштаба.
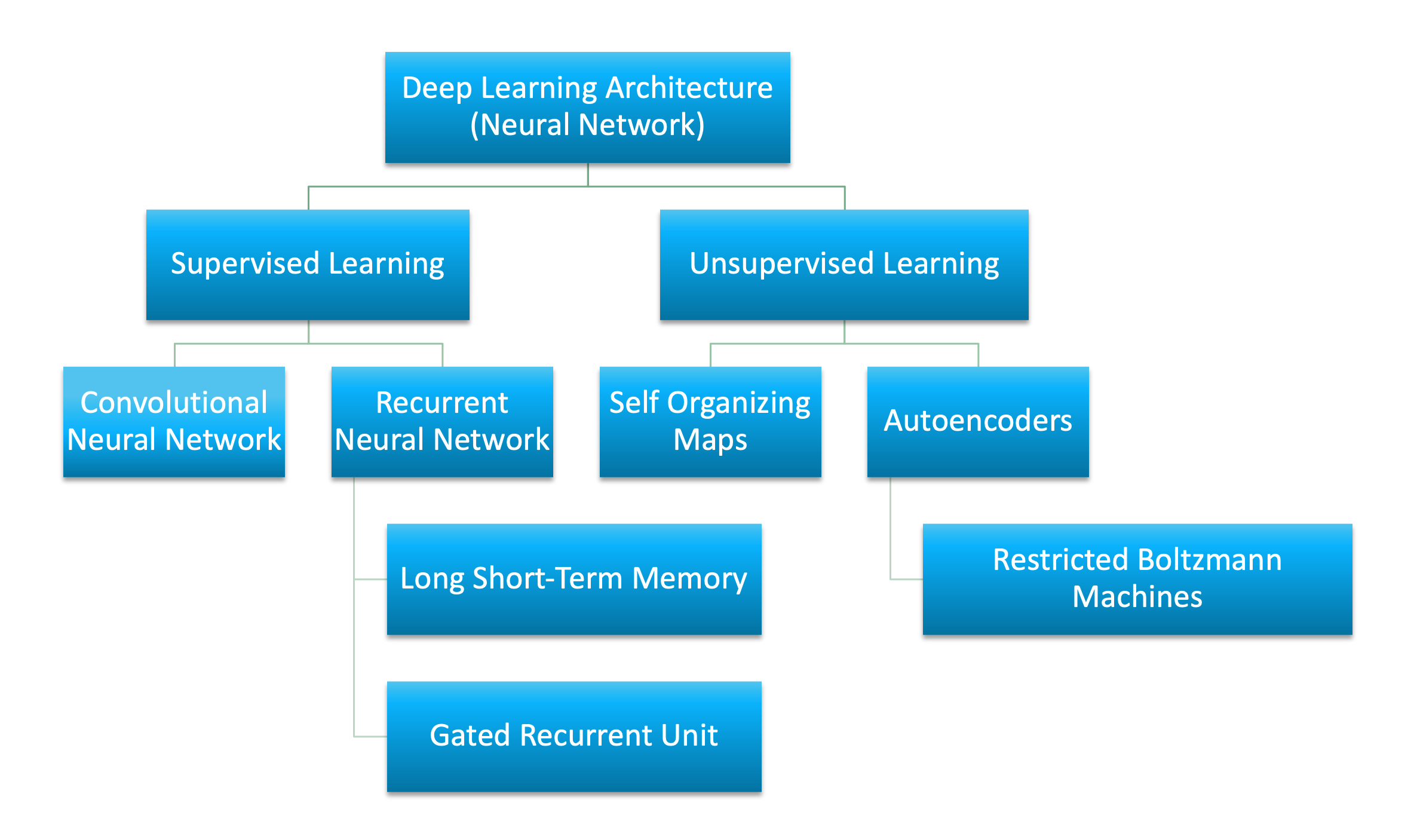
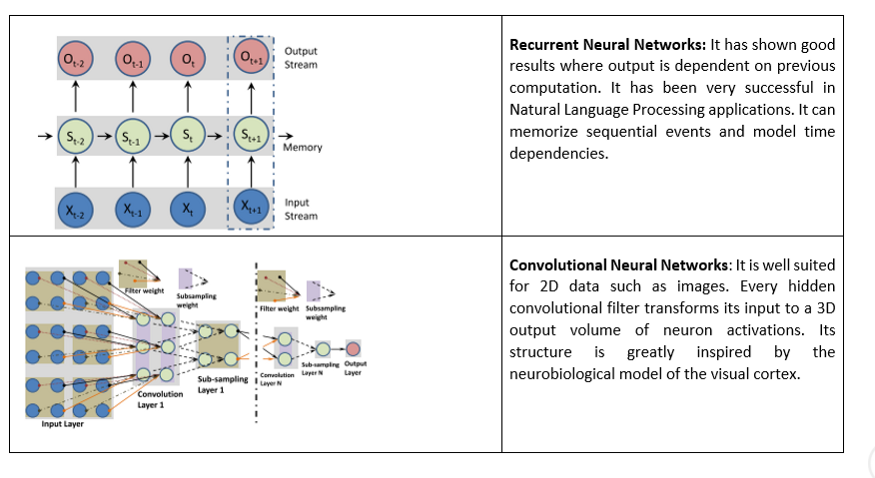
Виды нейросетей
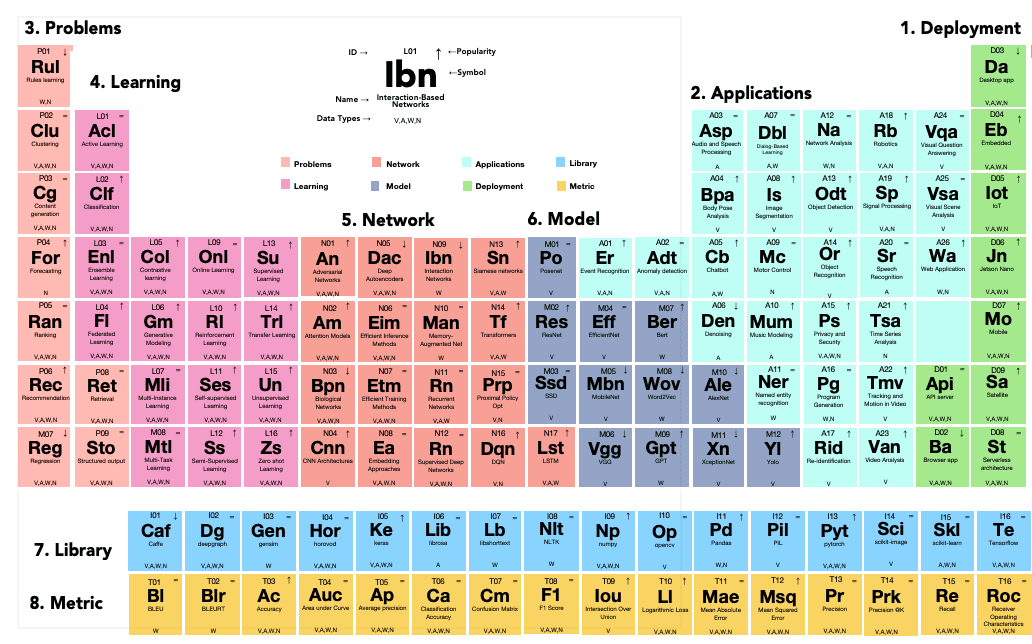
Библиотеки
Одно из наиболее информативных сравнений
Разработана монреальским университетом в 2007 году. Написана специально для символьных вычислений с функциями многократной вложенности.
- : прозрачные механизмы распараллеливания, возможность генерации кода на C, тесная интеграция с numpy
Написан Google на C++ . Единственная библиотека, использующая графы как основной объект. (точнее, тензорные графы, tensor networks). Остальные являются по сути библиотеками для символьных вычислений.
- : лёгкая масштабируемость, функциональность, идеально подходит для многомерных данных
Изначально написан на C как библиотека для LUA (привет любителям Lineage). Включает широкие возможности распараллеливания на GPU и CPU. Основная структура Dynamic Computational Graph
- : гибкость, быстрая обучаемость моделей, широкие возможности отладки (debugging)
Обычно используется как надстройка над theano, tensorflow. Написана на python.
- : быстрое , устойчивое и простое прототипирование
Пример СNN
CNN (Convolutional Neural Network, Свёрточные нейросети) - специальная архитектура искусственных нейронных сетей, предложенная Яном Лекуном в 1988 году, исспользуется в основном для обработки визуальной информации (изображений).
Типичная архитектура
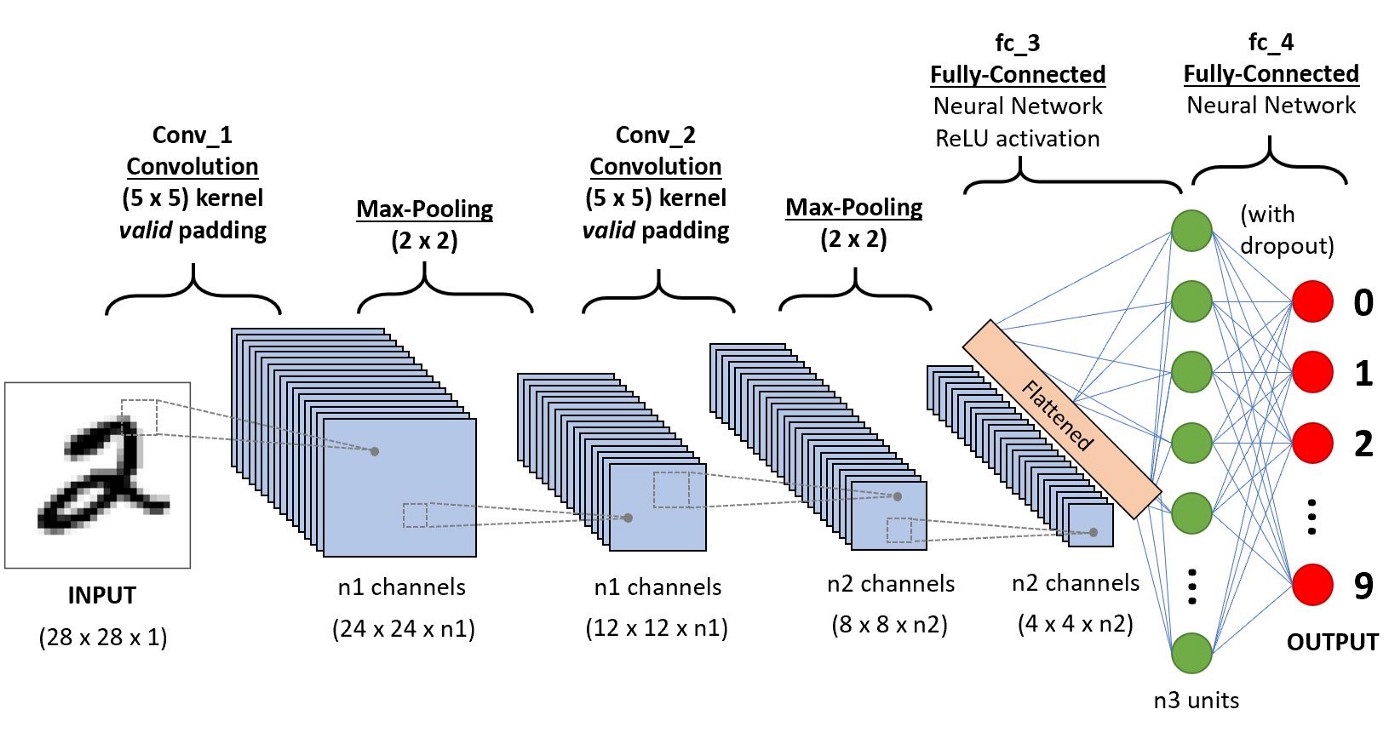
Пример работает с набором данных cifar и использует библиотеку pytorch.