Проверка гипотез и анализ правдоподобия
Содержание
- использованы материалы курса https://github.com/Intelligent-Systems-Phystech/psad
Введение. Библиотека statsmodels
В python для всевозможных задач статистического оценивания используется стандартная библиотека statsmodels Раньше была частью scipy , выделилась в самостоятельную, чтоб сделать основным объектом классы статистических моделей. Например , OLS - ordinary least squares , WLS - weighted least squares , RecursiveLS
Для описания матриц плана (design matrices) в ней используется библиотека patsy
Пример
Код к примеру
Пример использует так называемые данные Герри по социальной статистике во Франции в 1830х.
df = sm.datasets.get_rdataset("Guerry", "HistData").data
df.describe()
| dept | Crime_pers | Crime_prop | Literacy | Donations | Infants | Suicides | Wealth | Commerce | Clergy | Crime_parents | Infanticide | Donation_clergy | Lottery | Desertion | Instruction | Prostitutes | Distance | Area | Pop1831 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 86.000000 | 86.000000 | 86.000000 | 86.000000 | 86.000000 | 86.000000 | 86.000000 | 86.000000 | 86.000000 | 86.000000 | 86.000000 | 86.000000 | 86.000000 | 86.000000 | 86.000000 | 86.000000 | 86.000000 | 86.000000 | 86.000000 | 86.000000 |
| mean | 46.883721 | 19754.406977 | 7843.058140 | 39.255814 | 7075.546512 | 19049.906977 | 36522.604651 | 43.500000 | 42.802326 | 43.430233 | 43.500000 | 43.511628 | 43.500000 | 43.500000 | 43.500000 | 43.127907 | 141.872093 | 207.953140 | 6146.988372 | 378.628721 |
| std | 30.426157 | 7504.703073 | 3051.352839 | 17.364051 | 5834.595216 | 8820.233546 | 31312.532649 | 24.969982 | 25.028370 | 24.999549 | 24.969982 | 24.948297 | 24.969982 | 24.969982 | 24.969982 | 24.799809 | 520.969318 | 109.320837 | 1398.246620 | 148.777230 |
| min | 1.000000 | 2199.000000 | 1368.000000 | 12.000000 | 1246.000000 | 2660.000000 | 3460.000000 | 1.000000 | 1.000000 | 1.000000 | 1.000000 | 1.000000 | 1.000000 | 1.000000 | 1.000000 | 1.000000 | 0.000000 | 0.000000 | 762.000000 | 129.100000 |
| 25% | 24.250000 | 14156.250000 | 5933.000000 | 25.000000 | 3446.750000 | 14299.750000 | 15463.000000 | 22.250000 | 21.250000 | 22.250000 | 22.250000 | 22.250000 | 22.250000 | 22.250000 | 22.250000 | 23.250000 | 6.000000 | 121.383000 | 5400.750000 | 283.005000 |
| 50% | 45.500000 | 18748.500000 | 7595.000000 | 38.000000 | 5020.000000 | 17141.500000 | 26743.500000 | 43.500000 | 42.500000 | 43.500000 | 43.500000 | 43.500000 | 43.500000 | 43.500000 | 43.500000 | 41.500000 | 33.000000 | 200.616000 | 6070.500000 | 346.165000 |
| 75% | 66.750000 | 25937.500000 | 9182.250000 | 51.750000 | 9446.750000 | 22682.250000 | 44057.500000 | 64.750000 | 63.750000 | 64.750000 | 64.750000 | 64.750000 | 64.750000 | 64.750000 | 64.750000 | 64.750000 | 113.750000 | 289.670500 | 6816.500000 | 444.407500 |
| max | 200.000000 | 37014.000000 | 20235.000000 | 74.000000 | 37015.000000 | 62486.000000 | 163241.000000 | 86.000000 | 86.000000 | 86.000000 | 86.000000 | 86.000000 | 86.000000 | 86.000000 | 86.000000 | 86.000000 | 4744.000000 | 539.213000 | 10000.000000 | 989.940000 |
Удалим строки с пустыми значениями с помощью dropna()
vars = ['Department', 'Lottery', 'Literacy', 'Wealth', 'Region']
df = df.dropna()[vars]
df[-5:]
| Department | Lottery | Literacy | Wealth | Region | |
|---|---|---|---|---|---|
| 80 | Vendee | 68 | 28 | 56 | W |
| 81 | Vienne | 40 | 25 | 68 | W |
| 82 | Haute-Vienne | 55 | 13 | 67 | C |
| 83 | Vosges | 14 | 62 | 82 | E |
| 84 | Yonne | 51 | 47 | 30 | C |
Постановка задачи
Будет использоваться модель обычного метода наименьших квадратов OLS. Решается задача регрессии лотерейных ставок в королевской лотерее Франции в 1820х против показателей грамотности с учётом материального достатка населения. При этом в правой части регерессионного уравнения придётся учитывать "пустые" переменные, которые тем не менее вносят неоднородность в данные по департаментам.
План-матрицы
Для большинства моделей из statsmodels придётся определить 2 план-матрицы - для зависимых (endogenous, response, dependent) и независимых (exogenous, independent, predictor, regressor) переменных. Регрессионные МНК коэффиценты вычисляются как обычно:
где y имеет размер N * 1 - это данные из столбца Lottery X размера N * 7 - столбцы Wealth , Literacy и 4 бинарных, отвечающих за регионы.
Используется функция dmatrices библиотеки patsy для формирования план-матриц регрессионных моделей. Там используется синтаксис языка R .
y, X = dmatrices('Lottery ~ Literacy + Wealth + Region', data=df, return_type='dataframe')
y
| Lottery | |
|---|---|
| 0 | 41.0 |
| 1 | 38.0 |
| 2 | 66.0 |
| 3 | 80.0 |
| 4 | 79.0 |
| ... | ... |
| 80 | 68.0 |
| 81 | 40.0 |
| 82 | 55.0 |
| 83 | 14.0 |
| 84 | 51.0 |
85 rows × 1 columns
X
| Intercept | Region[T.E] | Region[T.N] | Region[T.S] | Region[T.W] | Literacy | Wealth | |
|---|---|---|---|---|---|---|---|
| 0 | 1.0 | 1.0 | 0.0 | 0.0 | 0.0 | 37.0 | 73.0 |
| 1 | 1.0 | 0.0 | 1.0 | 0.0 | 0.0 | 51.0 | 22.0 |
| 2 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 13.0 | 61.0 |
| 3 | 1.0 | 1.0 | 0.0 | 0.0 | 0.0 | 46.0 | 76.0 |
| 4 | 1.0 | 1.0 | 0.0 | 0.0 | 0.0 | 69.0 | 83.0 |
| ... | ... | ... | ... | ... | ... | ... | ... |
| 80 | 1.0 | 0.0 | 0.0 | 0.0 | 1.0 | 28.0 | 56.0 |
| 81 | 1.0 | 0.0 | 0.0 | 0.0 | 1.0 | 25.0 | 68.0 |
| 82 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 13.0 | 67.0 |
| 83 | 1.0 | 1.0 | 0.0 | 0.0 | 0.0 | 62.0 | 82.0 |
| 84 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 47.0 | 30.0 |
85 rows × 7 columns
Важно заметить, что dmatrices
- разделила Region на несколько индикаторных признаков ({1,0})
- добавила константу к независимым переменным (exogenous)
- возвращает pandas dataframe вместо обычного numpy array и позволяет сохранять описательные данные.
Типичная последовательность действий
Как правило работа со statsmodels состоит из 3 этапов :
- выбор класса статистических моделей
- обучение модели с помощью соответствующего метода
- изучеие полученных коэффицентов с помощью summary()
Для МНК (OLS) это выглядит так:
mod = sm.OLS(y, X) # Describe model
res = mod.fit() # Fit model
print(res.summary()) # Summarize model, like df.describe()
OLS Regression Results
==============================================================================
Dep. Variable: Lottery R-squared: 0.338
Model: OLS Adj. R-squared: 0.287
Method: Least Squares F-statistic: 6.636
Date: Tue, 12 Apr 2022 Prob (F-statistic): 1.07e-05
Time: 02:44:16 Log-Likelihood: -375.30
No. Observations: 85 AIC: 764.6
Df Residuals: 78 BIC: 781.7
Df Model: 6
Covariance Type: nonrobust
===============================================================================
coef std err t P>|t| [0.025 0.975]
-------------------------------------------------------------------------------
Intercept 38.6517 9.456 4.087 0.000 19.826 57.478
Region[T.E] -15.4278 9.727 -1.586 0.117 -34.793 3.938
Region[T.N] -10.0170 9.260 -1.082 0.283 -28.453 8.419
Region[T.S] -4.5483 7.279 -0.625 0.534 -19.039 9.943
Region[T.W] -10.0913 7.196 -1.402 0.165 -24.418 4.235
Literacy -0.1858 0.210 -0.886 0.378 -0.603 0.232
Wealth 0.4515 0.103 4.390 0.000 0.247 0.656
==============================================================================
Omnibus: 3.049 Durbin-Watson: 1.785
Prob(Omnibus): 0.218 Jarque-Bera (JB): 2.694
Skew: -0.340 Prob(JB): 0.260
Kurtosis: 2.454 Cond. No. 371.
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
res.params
Intercept 38.651655 Region[T.E] -15.427785 Region[T.N] -10.016961 Region[T.S] -4.548257 Region[T.W] -10.091276 Literacy -0.185819 Wealth 0.451475 dtype: float64
res.rsquared
0.3379508691928823
Анализ и визуализация результатов
statsmodels содержит также много тестов для оценки качества поолученной (обученной) статистической модели.
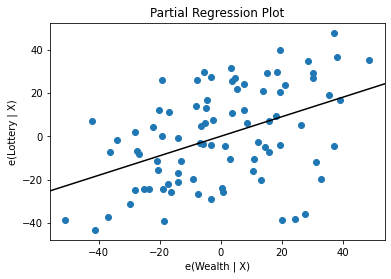
И инструменты для отрисовки графиков приближений модели.
sm.graphics.plot_partregress('Lottery', 'Wealth', ['Region', 'Literacy'],
....: data=df, obs_labels=False)