Исполнитель "Черепаха" (ч.2)
Содержание
Генерация случайных чисел
Python порождает случайные числа на основе формулы, так что они не на самом деле случайные, а, как говорят, псевдослучайные.
Модуль random позволяет генерировать случайные числа. Прежде чем использовать модуль, необходимо подключить его с помощью инструкции:
from random import *
Пока вам достаточно знать две функции из этого модуля:
random() |
возвращает псевдослучайное число типа float от 0.0 до 1.0 |
randint(a, b) |
возвращает псевдослучайное целое число в промежутке [a, b] включая его границы |

Списки
Большинство программ работает не с отдельными переменными, а с набором переменных. Например, программа может обрабатывать информацию об учащихся класса, считывая список учащихся с клавиатуры или из файла, при этом изменение количества учащихся в классе не должно требовать модификации исходного кода программы.
Для хранения таких данных можно использовать структуру данных, называемую в Питоне список. Список представляет собой последовательность элементов, проиндексированных от 0. Список можно задать перечислением элементов в квадратных скобках, например, список можно задать так:
Primes = [2, 3, 5, 7, 11, 13]
Rainbow = ['Red', 'Orange', 'Yellow', 'Green', 'Blue', 'Indigo', 'Violet']
В списке Primes — 6 элементов, а именно, Primes[0] == 2, Primes[1] == 3, Primes[2] == 5, Primes[3] == 7,
Primes[4] == 11, Primes[5] == 13. Список Rainbow состоит из 7 элементов, каждый из которых является строкой.
Также как и символы строки, элементы списка можно индексировать отрицательными числами с конца, например,
Primes[-1] == 13, Primes[-6] == 2.
Длину списка, то есть количество элементов в нем, можно узнать при помощи функции len, например, len(A) == 6.
Рассмотрим несколько способов создания и считывания списков. Пустой, т.е. не имеющий элементов список, можно создать следующим образом:
A = []
Для добавления элементов в конец спискаиспользуется функция append. Если программа получает на вход количество
элементов в списке n, а потом n элементов списка по одному в отдельной строке, то организовать считывание списка
можно так:
A = []
for i in range(int(input()):
A.append(int(input())
В этом примере создается пустой список, далее считывается количество элементов в списке, затем по одному считываются элементы списка и добавляются в его конец.
Для списков целиком определены следующие операции: конкатенация списков (добавление одного списка в конец другого) и повторение списков (умножение списка на число). Например:
A = [1, 2, 3]
B = [4, 5]
C = A + B
D = B * 3
В результате список C будет равен [1, 2, 3, 4, 5], а список D будет равен [4, 5, 4, 5, 4, 5]. Это позволяет по-
другому организовать процесс считывания списков: сначала считать размер списка и создать список из нужного числа
элементов, затем организовать цикл по переменной i начиная с числа 0 и внутри цикла считывается i-й элемент списка:
A = [0] * int(input())
for i in range(len(A)):
A[i] = int(input())
Вывести элементы списка A можно одной инструкцией print(A), при этом будут выведены квадратные скобки вокруг
элементов списка и запятые между элементами списка. Такой вывод неудобен, чаще требуется просто вывести все элементы
списка в одну строку или по одному элементу в строке. Приведем два примера, также отличающиеся организацией цикла:
for i in range(len(A)):
print(A[i])
Здесь в цикле меняется индекс элемента i, затем выводится элемент списка с индексом i.
for elem in A:
print(elem, end = ' ')
В этом примере элементы списка выводятся в одну строку, разделенные пробелом, при этом в цикле меняется не индекс
элемента списка, а само значение переменной. Например, в цикле for elem in ['red', 'green', 'blue'] переменная elem
будет последовательно принимать значения 'red', 'green', 'blue'.
Методы split и join
Выше мы рассмотрели пример считывания списка, когда каждый элемент расположен на отдельной строке. Иногда бывает удобно
задать все элементы списка при помощи одной строки. В такой случае используется метод split, определённый в строковом
типе:
A = input().split()
Если при запуске этой программы ввести строку 1 2 3, то список A будет равен ['1', '2', '3']. Обратите внимание, что
список будет состоять из строк, а не из чисел. Если хочется получить список именно из чисел, то можно затем элементы
списка по одному преобразовать в числа:
for i in range(len(A)):
A[i] = int(A[i])
Используя функции языка map и list то же самое можно сделать в одну строку:
A = list(map(int, input().split()))
Объяснений, как работает этот пример, пока не будет. Если нужно считать список действительных чисел, то нужно заменить тип int на тип float.
У метода split есть необязательный параметр, который определяет, какая строка будет использоваться в качестве
разделителя между элементами списка. Например, вызов метода split('.') для строки вернет список, полученный
разрезанием этой строки по символам '.'.
Используя «обратные» методы можно вывести список при помощи однострочной команды. Для этого используется метод строки
join. У этого метода один параметр: список строк. В результате создаётся строка, полученная соединением элементов
списка (которые переданы в качестве параметра) в одну строку, при этом между элементами списка вставляется разделитель,
равный той строке, к которой применяется метод. Например, программа
A = ['red', 'green', 'blue']
print(' '.join(A))
print(''.join(A))
print('***'.join(A))
выведет строки red green blue, redgreenblue и red***green***blue.
Если же список состоит из чисел, то придется использовать еще и функцию map. То есть вывести элементы списка чисел, разделяя их пробелами, можно так:
print(' '.join(map(str, A)))
Срезы списков
Со списками, так же как и со строками, можно делать срезы. А именно:
A[i:j] |
срез из j-i элементов A[i], A[i+1], ..., A[j-1]. |
A[i:j:-1] |
срез из i-j элементов A[i], A[i-1], ..., A[j+1] (то есть меняется порядок элементов). |
A[i:j:k] |
срез с шагом k: A[i], A[i+k], A[i+2*k],... . Если значение k меньше 0, то элементы идут в противоположном порядке. |
Каждое из чисел i или j может отсутствовать, что означает «начало строки»/ или «конец строки»/
Списки, в отличии от строк, являются изменяемыми объектами: можно отдельному элементу списка присвоить новое значение. Но можно менять и целиком срезы. Например:
A = [1, 2, 3, 4, 5]
A[2:4] = [7, 8, 9]
Получится список, у которого вместо двух элементов среза A[2:4] вставлен новый список уже из трех элементов. Теперь список стал равен [1, 2, 7, 8, 9, 5].
A = [1, 2, 4, 5, 6, 7]
A[::-2] = [10, 20, 30, 40]
Получится список [40, 2, 30, 4, 20, 6, 10]. Здесь A[::-2] — это список из элементов A[-1], A[-3], A[-5], A[-7], которым присваиваются значения 10, 20, 30, 40 соответственно.
Если не непрерывному срезу (то есть срезу с шагом k, отличному от 1), присвоить новое значение, то количество элементов в старом и новом срезе обязательно должно совпадать, в противном случае произойдет ошибка ValueError.
Обратите внимание, A[i] — это элемент списка, а не срез!
Операции со списками
| операция | действие |
|---|---|
x in A |
Проверить, содержится ли элемент в списке. Возвращает True или False. |
x not in A |
То же самое, что not(x in A). |
min(A) |
Наименьший элемент списка. Элементы списка могут быть числами или строками, для строк сравнение элементов проводится в лексикографическом порядке. |
max(A) |
Наибольший элемент списка. |
sum(A) |
Сумма элементов списка, элементы обязательно должны быть числами. |
A.index(x) |
Индекс первого вхождения элемента x в список, при его отсутствии генерирует исключение ValueError. |
A.count(x) |
Количество вхождений элемента x в список. |
A.append(x) |
Добавить в конец списка A элемент x. |
A.insert(i, x) |
Вставить в список A элемент x на позицию с индексом i. Элементы списка A, которые до вставки имели индексы i и больше сдвигаются вправо. |
A.extend(B) |
Добавить в конец списка A содержимое списка B. |
A.pop() |
Удалить из списка последний элемент, возвращается значение удаленного элемента. |
A.pop(i) |
Удалить из списка элемент с индексом i, возвращается значение удаленного элемента. Все элементы, стоящие правее удаленного, сдвигаются влево. |
Генераторы списков
Для создания списка, заполненного одинаковыми элементами, можно использовать оператор повторения списка, например:
A = [0] * n
Для создания списков, заполненных по более сложным формулам можно использовать list comprehensions или генераторы списков (в функциональном программировании они называются "списковые включения"): выражения, позволяющие заполнить новый список значениями некоторого выражения (формулы).
Общий вид генератора следующий: [выражение for переменная in список ], где
переменная — идентификатор некоторой переменной, список — список значений,
который принимает данная переменная (как правило, полученный при помощи функции range),
выражение — некоторое выражение, которым будут заполнены элементы списка,
как правило, зависящее от использованной в генераторе переменной.
Вот несколько примеров использования генераторов.
Квадраты целых чисел:
A = [i ** 2 for i in range(1, n + 1)]
Вот так можно получить список, заполненный случайными числами от -99 до 99
(используя функцию randint из модуля random):
A = [randint(-99, 99) for i in range(n)]
Расширенная форма генератора списка позволяет выполнять отсев по значению.
Например, здесь список B будет состоять из элементов списка A, которые больше нуля:
B = [x for x in A if x > 0]
Упражнение
Посмотрите на шрифт для написания почтового индекса на конвертах:
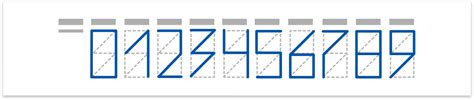
Воспользуйтесь списками кортежей, чтобы задать рисование Черепашкой таких цифр. Нарисуйте на экране индекс 141700.

Работа с текстовыми файлами в Python
До этого для ввода информации мы использовали исключительно клавиатуру. При этом в большинстве случаев данные, считываемые программой, уже хранятся на носителе информации в виде файлов.
Для каждого файла, с которым необходимо производить операции ввода-вывода, нужно создать специальный объект – поток. Именно с потоками работают программы — использование такого дополнительного слоя абстракции позволяет прозрачно работать не только с текстовыми файлами, но и, например, с архивами.
Открытие файла
Открытие файла осуществляется функцией open, которой нужно передать два параметра. Первый параметр — строка, задающая
имя открываемого файла. Второй параметр — строка, укахывающая режим октрытия файла.
Существует три режима открытия файлов:
| Режим | Описание |
|---|---|
| "r" (read) | Файл открывается для чтения данных. |
| "w" (write) | Файл открываетсяна запись, при этом содержимое файла очищается. |
| "a" (append) | Файл открывается для добавления данных в конец файла. |
Если второй параметр не задан, то считается, что файл открывается в режиме чтения.
Функция open возвращает ссылку на файловый объект, которую нужно записать в переменную, чтобы потом через данный объект работать с этим файлом. Например:
input = open('input.txt', 'r')
output = open('output.txt', 'w')
Здесь открыто два файла (один на чтение, другой на запись) и создано два связанных с ними объекта.
Чтение данных из файла
Для файла, открытого на чтение данных, можно несколько методов, позвозволяющих считывать данные. Мы рассмотри
три из них: readline, readlines, read.
Метод readline() считывает одну строку из файла (до символа конца строки 'n', возвращается считанная строка вместе с
символом 'n'). Если считывание не было успешно (достигнут конец файла), то возвращается пустая строка. Для удаления
символа 'n' из конца файла удобно использовать метод строки rstrip(). Например:
s = s.rstrip().
Метод readlines() считывает все строки из файла и возвращает список из всех считанных строк (одна строка — один
элемент списка). При этом символы 'n' остаются в концах строк.
Метод read() считывает все содержимое из файла и возвращает строку, которая может содержать символы 'n'. Если методу
read передать целочисленный параметр, то будет считано не более заданного количества байт. Например, считывать файл
побайтово можно при помощи метода read(1).
Вывод данных в файл
Данные выводятся в файл при помощи метода write, которому в качестве параметра передается одна строка. Этот метод не
выводит символ конца строки 'n' (как это делает функция print при стандартном выводе), поэтому для перехода на новую
строку в файле необходимо явно вывести символ 'n'.
Выводить данные в файл можно и при помощи print, если передать функции еще один именованный параметр file. Например:
output = open('output.txt', 'w')
print(a, b, c, file=output)
Закрытие файла
После окончания работы с файлом необходимо закрыть его при помощи метода close().
Чтобы не забыть это сделать можно воспользоваться менеджером контекста with.
with open('input.txt') as file:
Примеры работы с файлами
Следующая программа считывает все содержимое файла input.txt, записывает его
в переменную s, а затем выводит ее в файл output.txt.
inp = open('input.txt', 'r')
out = open('output.txt', 'w')
s = inp.read()
out.write(s)
inp.close()
out.close()
Для простого считывания содержимого файла можно использовать то, что сам файл является итерируемым по строкам объектом:
with open('input.txt') as file:
for line in file:
print('line: "', line, '"')
Упражнение
Перенесите описание способа рисования почтовых цифр (списки движений) в файл. Пусть черепаха считывает "шрифт" из файла.
Физическое моделирование материальной точки
Используя оператор turtle.goto(x, y) заставьте черепашку двигаться в равномерном поле тяжести,
отталкиваясь от поверхности (уровень y=0).
Основные формулы для расчёта нового местоположения черепшки:
x += Vx*dt
y += Vy*dt + ay*dt**2/2
Vy += ay*dt

Черепаха как объект
При помощи конструктора turtle.Turtle() можно создать новый объект черепахи.
Если поместить эти объекты в список, а потом циклически двигать каждую черепаху
на нельшое смещение, возникает эффект одновременного движения:
from random import randint
import turtle
number_of_turtles = 5
steps_of_time_number = 100
pool = [turtle.Turtle(shape='turtle') for i in range(number_of_turtles)]
for unit in pool:
unit.penup()
unit.speed(50)
unit.goto(randint(-200, 200), randint(-200, 200))
for i in range(steps_of_time_number):
for unit in pool:
unit.forward(2)
При помощи подобного кода заставье черепах вести себя как идеальный газ в сосуде. Если это слишком просто, то как реальный газ.
