Базы данных
Содержание
Базы данных и СУБД
Под базой данных (БД) понимается совокупность данных, систематизированных таким образом, чтобы эти данные могли быть найдены и обработаны с помощью ЭВМ. Вместе с понятием баз данных рассматривается понятие системы управления базами данных (СУБД). СУБД – совокупность программных и лингвистических средств общего или специального назначения, обеспечивающих управление созданием и использованием баз данных. Другими словами, это комплекс программ, позволяющих создать БД и манипулировать данными. Система обеспечивает безопасность, надёжность хранения и целостность данных, а также предоставляет средства для администрирования БД.
Базы данных классифицируют по разным критериям. Один из критериев – модель данных – абстрактное, самодостаточное, логическое определение объектов, операторов и прочих элементов, в совокупности составляющих абстрактную машину доступа к данным, с который взаимодействует пользователь. Одна из распространенных на сегодняшний день моделей является реляционная модель. В реляционных моделях баз данных широко используются три ключевых термина:
- отношение – таблица со столбцам и строками;
- атрибуты – именованные столбцы отношения;
- домен – набор значений, которые могут принимать атрибуты.
В реляционной логике отношения обычно называют сущностями, а атрибуты с совпадающими доменами - связями.
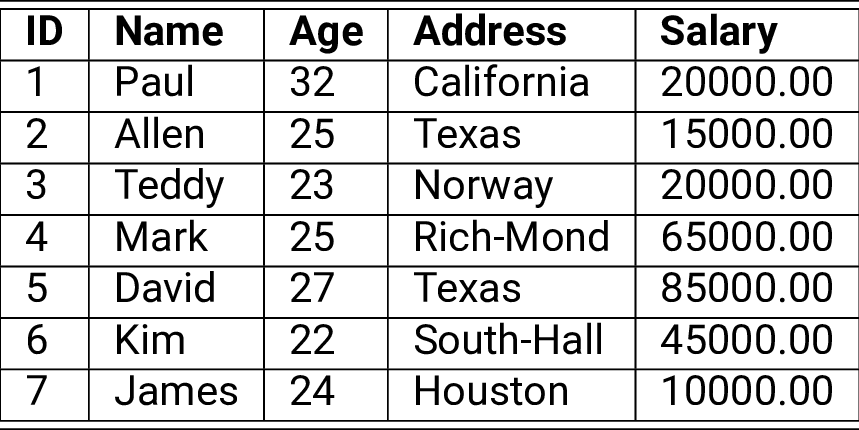
Выше представлена основная структура данных реляционной модели – таблица. Информация о конкретном объекте представлена в строках (кортежах) и столбцах. Реляционная БД представлена набором таких таблиц – отношений, каждое отношение представляет собой набор кортежей. В столбцах перечислены различные атрибуты объекта (в примере выше: ID, имя, возраст, адрес, зарплата).
Все отношения должны придерживаться некоторых правил.
- Упорядочение столбцов не существенно в таблице.
- В таблице не может быть одинаковых кортежей.
- Каждый кортеж будет содержать одно значение для каждого из атрибутов.
Реляционные базы данных называются так потому, что построены по принципам реляционной логики ( в ней, например, в отличие от обычной булевой, не 2 значения, а 3: кроме true и false там есть значение dnk - do not know ) Подробнее о реляционной логике см, например книгу Гарсия-Молина , Ульман: Системы баз данных. Полный курс
Нам же сейчас важно уяснить следующий основной принцип. Любая реляционная база данных представляет собой связный граф. Его вершины - это сущности (таблицы/отношения). А ребра - это связи (столбцы/признаки с совпадающими доменами).
Любое значение, имеющее место в двух разных записях (принадлежащих к одной таблице или к разным), подразумевает взаимосвязь между этими записями.
За 1 базу данных отвечает 1 связный граф - это означает, что по общим значениям атрибутов мы можем от любой сущности за конечное число переходов добраться до любой другой.
См на рисунке
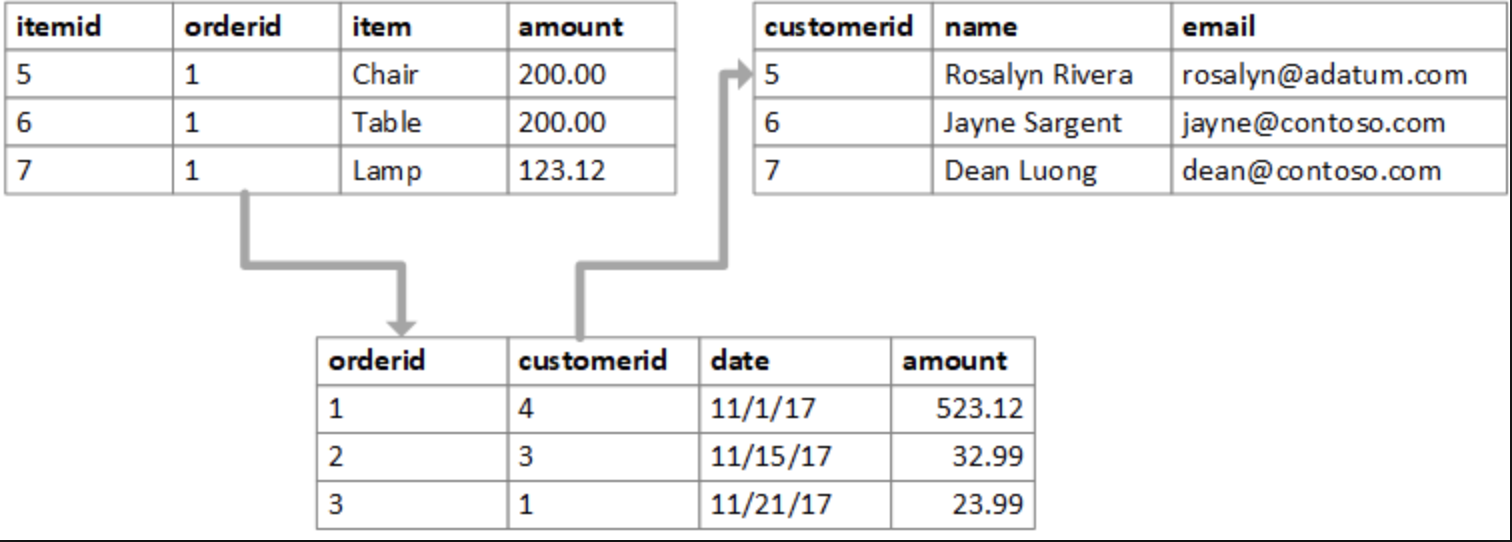
вверху слева представлены товары на складе, справа - покупатели. Внизу - покупки. У каждой покупки номер товара совпадает с одним из значений в таблице товаров, а номер покупателя -с таковым в таблице покупателей.
Таблицы могут иметь назначенный единственный атрибут или набор атрибутов, которые могут действовать как ключ (primary key). Ключ используется для однозначной идентификации каждого кортежа в таблице. В примере выше «ID» является ключом, т.к. это уникальный номер для каждого сотрудника. Обычно ключи используют для объединения данных из нескольких таблиц. Например¸ добавим еще одну таблицу:
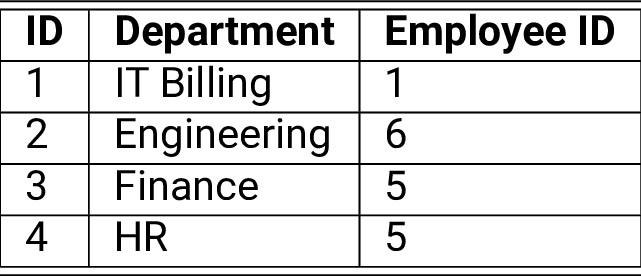
Атрибут «ID» связывает данные из таблицы «company» связывает ее с данными из таблицы «department» через атрибут «Employee ID».
Язык запросов SQL и СУБД sqlite3
Наиболее распространенным языком запросов в реляционной модели является язык структурированных запросов (structured query language, SQL). Для удобства последовательность ззапросов объединяют в скрипты с расширением sql. Для обращения к БД нам понадобится клиентская часть СУБД. Для этих целей в этом курсе используется компактная встраиваемая СУБД SQLite. «Встраиваемая» означается, что SQLite не является клиент-серверным приложением. Движок представляет собой библиотеку, с которой компонуется программа. База данных, с которой работает программа, хранится на там же компьютере в единственном файле. Клиентской частью является кроссплатформенная утилита командной строки sqlite3. Для работы с базой данных запустите утилиту, указав имя файла БД. Если файл не существует, то он будет создан
sqlite3 test.db
Запустив утилиту, вы попадете в интерактивный режим. Все команды утилиты начинаются с точки.
Ознакомиться со списком команд можно при помощи .help
sqlite> .help
Для завершения работы с утилитой введите .quit или сочетание клавиш ctrl+D.
Интерактивный режим утилиты позволяет как напрямую писать запросы на языке SQL, так и запускать на
исполнение sql файлы. Для запуска файла используется команда .read path/to/sql/file.
Для удобства используйте команды
sqlite> .mode column
sqlite> .headers on
Это позволит отображать результаты запросов в виде выравненных таблиц с названиями столбцов.
Синтакис SQL
Первое – SQL не является регистрозависимым, однако все ключевые слова и функции принято писать
заглавными буквами, а названия таблиц и атрибутов – маленькими.
Второе – комментарии. SQL поддерживает 2 типа комментариев: начинающиеся с -- и C-style
комментарии /* */, которые могут быть многострочными.
Третье – все выражения начинаются с ключевого слова и оканчиваются ;.
Типы данных
SQLite поддерживает следующие типы данных:
- NULL – пустое значение;
- INTEGER – 1, 2, 3, 4, 6 или 8 байтное знаковое число;
- REAL – 8-байтное число с плавающей запятой;
- TEXT – строка в кодировке UTF-8, UTF-16BE или UTF-16LE (зависит от базы данных);
- BLOB – массив двоичных данных, обычно нужен для хранения мультимедийных объектов и скомпилированного программного кода.
В отличие от других СУБД, SQLite не поддерживает явного указания размера целого числа. Использование типов данных с указанием размера автоматически приводится к INTEGER. Для текстовых типов данных происходит аналогичное приведение к TEXT, а указанное ограничение на длину текста опускается.
BOOLEAN в SQLite представлен типом INTEGER со значениями 0 и 1.
Отдельное внимание стоит уделить хранению даты/времени. В SQLite под это также нет специального типа. Однако TEXT, REAL и INTEGER могут быть использованы для этих целей.
В виде текста вермя хранится в формате YYYY-MM-DD HH:MM:SS.SSS, хотя миллисекунды можно опустить.
Для того, чтобы получить текущее время в этом представлении, можно использовать функцию DATETIME("now").
Полученный результат будет отображать текущее время по UTC (Coordinated Universal Time). Московское время – UTC+3.
Если необходимо получить локальное текущее время, то DATETIME("now", "localtime").
REAL хранит время в виде юлианской даты, т.е. количество суток, прошедших с полудня 24 ноября 4714 г. до н.э. по
григорианскому календарю. Дробная часть показывает время. Например, 2451545,25 есть 18 часов 1 января 2000 года.
Т.к. такой формат не особо читаемый, то функции DATE и TIME от такого дробного числа возвращают дату и время
соответственно.
INTEGER работает с широко известным UNIX timestamp. Timestamp показывает количество секунд, прошедших с 00:00:00 по UTC
1 января 1970 года (этот момент времени – UNIX epoch). Чтобы получить время в этом представлении, воспользуйтесь
STRFTIME("%s", "now"). Функция поддерживает и модификатор localtime. Для перевода в читаемый формат используйте:
DATETIME(timestamp, "unixepoch").
Создание, удаление и изменение таблиц
Для создания таблицы используется команда CREATE TABLE. Общий синтаксис команды:
CREATE TABLE table_name(
column1 datatype PRIMARY KEY,
column2 datatype,
column3 datatype,
.....
columnN datatype
);
Обратите внимание, что в таблице хотя бы один атрибут должен быть ключом. Рассмотрим несколько примеров
CREATE TABLE company(
id INT,
name TEXT,
age INT,
address TEXT,
salary REAL
);
CREATE TABLE department(
id INT,
dept TEXT,
emp_id INT
);
Данный запрос создаст простую таблицу, состоящую из 5 столбцов. Если в процессе работы вам необходимо удалить созданную таблицу, воспользуйтесь запросом
DROP TABLE company;
Однако, прежде чем перейти к заполнению заполнению, рассмотрим различные параметры, которые можно навесить на таблицу и ее атрибуты.
- NOT NULL указывает на то, что атрибут не может иметь пустое значение;
- DEFAULT позволяет задать атрибуту значение по умолчанию;
- UNIQUE делает значения атрибутов уникальным для каждой строки;
- PRIMARY KEY однозначно определяет каждую строку (может быть указан только у одного атрибута);
- FOREIGN KEY связывает столбец одной таблицы со столбцом другой таблицы;
- AUTOINCREMENT автоматически задает атриубуту увеличивающееся значение;
- CHECK проверяет, что значения атрибута удовлетворяют логическому выражению.
Модифицируем наши таблицы.
CREATE TABLE company(
id INT PRIMARY KEY NOT NULL,
name TEXT NOT NULL,
age INT NOT NULL,
address TEXT,
salary REAL DEFAULT 30000 CHECK(salary >= 0)
);
CREATE TABLE department(
id INT PRIMARY KEY NOT NULL,
dept TEXT NOT NULL,
emp_id INT NOT NULL,
FOREIGN KEY (emp_id) REFERENCES company (id)
);
Заметьте, что теперь department.emp_id и company.id связаны, и department.emp_id может содержать только те значения, что есть в company.id.
Для изменения таблицы есть команда ALTER TABLE.
В SQLite поддерживается 2 варианта: переименование таблицы и добавление столбца.
ALTER TABLE old_table RENAME TO new_table;
ALTER TABLE table_name ADD COLUMN column_definition;
Добавленный столбец не может быть UNIQUE или PRIMARY KEY. Если он NOT NULL, то обязательно
должны быть указаны значения по умолчанию.
Добавление строк
Для вставки строки используется INSERT.
INSERT INTO table_name (column1, column2, ...)
VALUES
(value1, value2, ...),
...
(value1, value2, ...);
Приведенный выше синтаксис позволяет вставить несколько строк с заданными значениями атрибутов.
(column1, column2, ...) указывает, для каких атрибутов задаются значения. Если задаются значения
для всех атрибутов, то (column1, column2, ...) можно опустить.
INSERT INTO company
VALUES
(1, 'Paul', 32, 'California', 20000.00),
(2, 'Allen', 25, 'Texas', 15000.00),
(3, 'Teddy', 23, 'Norway', 20000.00),
(4, 'Mark', 25, 'Rich-Mond ', 65000.00),
(5, 'David', 27, 'Texas', 85000.00),
(6, 'Kim', 22, 'South-Hall', 45000.00),
(7, 'James', 24, 'Houston', 10000.00);
INSERT INTO department
VALUES
(1, 'IT Billing', 1),
(2, 'Engineering', 6),
(3, 'Finance', 5),
(4, 'HR', 5);
Вы можете добавить в таблицы больше данных и не стесняйтесь экспериментировать с написанием запросов. Так вам будет проще разобраться с тем, как они работают.
Запрос SELECT
Запрос SELECT позволяет получить выборку данных из одной или нескольких таблиц. Кроме того
SELECT можно использовать для вычислений.
SELECT 1 + 1;
SELECT 10 / 5, 2 * 4;
Обычно запрос используется для получения данных из таблицы. Общий вид запроса следующий:
SELECT DISTINCT column_list
FROM table_list
JOIN table_name ON join_condition
WHERE search_condition
ORDER BY column_list
LIMIT count
OFFSET offset
GROUP BY column_name
HAVING group_filter;
SELECT является самым сложным запросом. Для простоты понимания разберем выражение постепенно.
SELECT name, salary FROM company;
Такой запрос создаст временную таблицу из столбцов company.name и company.salary, заполнив ее
значениями из таблицы company. Если нам необходимо просмотреть данные всех столбцов, то список
столбцов заменяется на *.
SELECT * FROM company;
ORDER BY позволяет отсортировать данные.
SELECT name, age, salary
FROM company
ORDER BY
age ASC,
salary DESC;
ASC и DES означают сортировку по возрастанию и убыванию соответственно.
DISTINCT убирает дублирующиеся строки. Сравните результаты двух запросов.
SELECT age FROM company;
SELECT DISTINCT age FROM company;
WHERE позволяет отфильтровать результаты путем вычисления логических выражений, объединенных
логическими AND и OR.
Примеры фильтров:
... WHERE column1 = 100;
... WHERE column2 NOT IN (1, 2, 3);
... WHERE column3 IS NULL;
... WHERE column4 BETWEEN 10 AND 20;
WHERE поддерживает еще пару выражений, которые мы пока опустим.
LIMIT позволяет ограничить количество строк в результате. Например, после сортировки работников по
атрибуту salary мы бы хотели видеть только топ 10 зарплат в компании. OFFSET позволяет сдвинуть
начало отсчета. Например,
LIMIT 10 OFFSET 5;
позволит посмотреть следующие топ 10 зарплат после топ 5.
GROUP BY выполняет группировку данных по указанным столбцам. При использовании группировки обычно
подсчитывают ту или иную статистику внутри каждой группы. Например, MAX, MIN, COUNT, AVG.
SELECT emp_id, COUNT(id)
FROM department
GROUP BY emp_id;
Первый столбец будет содержать id работников, а второй столбец — количество отделов,в которых он
работает. HAVING позволяет фильтровать результаты GROUP BY. Например
SELECT emp_id, COUNT(id)
FROM department
GROUP BY emp_id
HAVING COUNT(id) = 1;
оставит только тех сотрудников, которые работают только в одном отделе.
JOIN
JOIN позволяет выполнять SELECT, соединяя данные из нескольких таблиц.
Первый вид JOIN это CROSS JOIN. Такой запрос строит декартово произведение, т.е. каждая строка
первой таблицы будет сопоставлена каждой строке второй таблицы. Итого N × M строк, где N и M —
количество строк в первой и второй таблице соответственно.
SELECT *
FROM company, department;
SELECT *
FROM company
CROSS JOIN department;
Приведенные два запроса эквивалентны, но лучше использовать второй, т.к. он явно указывает тип объединения.
Следующий вид — INNER JOIN. Он строит результат только из тех пар строк, которые удовлетворяют
предикату, среди всех возможных пар.
SELECT name, dept
FROM company
INNER JOIN department
ON company.id = department.emp_id;
LEFT JOIN для каждой строки из первой таблицы выбирает все подходящие строки из второй.
Если таковой не существует, парой к строке из первой таблицы берется пустая строка.
SELECT name, dept
FROM company
LEFT JOIN department
ON company.id = department.emp_id;
Как можно увидеть, в столбце name теперь есть все сотрудники. Однако столбец dept заполнен
только у тех сотрудников, про которых есть информация в department.
В общем виде SQL поддерживает еще RIGHT JOIN (противоположность LEFT JOIN) и FULL OUTER JOIN
(объединение результатов LEFT JOIN и RIGHT JOIN), однако в SQLite их нет.
Расширенная работа со строками таблицы
Вы уже знаете, что в таблицу можно вручную добавлять значения. Однако, бывает потребность заполнить
таблицу, используя данные из другой таблицы. Для этих целей INSERT поддерживает полноценный
запрос SELECT.
INSERT INTO table_name
SELECT your_select_query...;
Это может быть использовано для сохранения результатов SELECT с последующим изменением или чтобы
обойти ограничения SQLite (например заменить отсутствующий запрос ALTER TABLE RENAME COLUMN).
Для удаления строк используется DELETE.
DELETE FROM table_name
WHERE search_condition;
Изменение данных в уже существущих строках выполняется при помощи UPDATE.
Его вид:
UPDATE table_name
SET
column1 = value1,
column2 = value2,
...
WHERE search_condition
ORDER BY column_or_expression
LIMIT row_count OFFSET offset;
ORDER BY и LIMIT выполняют те же роли, что и в SELECT запросе.
Упражнения
Упражнение №1
Создайте таблицы с указанными столбцами и заполните их произвольными данными. Напоминаю, что весь текст хранится в юникоде, соответственно кирилица поддерживается. Если есть желание, то названия столбцов и данные таблицы можно вбивать на русском языке.
- Books (id, author, title, publish_year)
- Readers (id, name)
- Records (reader_id, book_id, taking_date, returning_date)
Обратите внимание, что данные в таблице Records должны быть связаны с данными из других таблиц.
Упражнение №2
Постройте select запросы:
- Запрос возвращает id и названия книг, находящихся в данный момент на руках у читателей.
- Запрос возвращает имена читателей и названия книг, которые они когда либо брали.
- Запрос возвращает количество книг для каждого автора.
Упражнение №3*
Реализуйте запрос FULL OUTER JOIN и проверьте его на данных из примеров.
Подсказка: вам поможет UNION ALL, который объединяет результаты двух select запросов,
включая дублирующиеся строки. Или UNION, который объединяет результаты двух select запросов,
исключая дублирующиеся строки.
SELECT ...
UNION ALL
SELECT ...